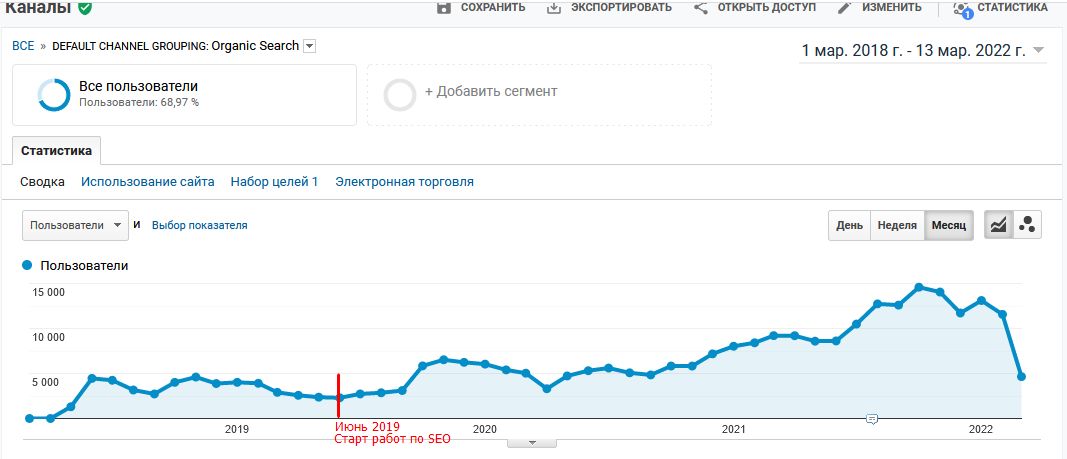
[!] Над проектом работал с мая 2019 года. Работы проделано очень много, в статье не буду расписывать каждый шаг, каждое ТЗ, т.к. это невозможно охватить одной статьей. Здесь только общие цифры и действия.
1. Исходные данные.
- регион — Россия;
- обычный контекстный проект — цифровая библиотека, не коммерческая;
- ежемесячный бесплатный поисковый трафик на момент старта — 50 000 - 60 000 сессий;
- старт работ — май 2019;
- продолжительность работы по SEO — 3 года.
2. Цели.
- улучшение взаимодействия юзера с порталом (рост вовлеченности, снижение отказов и тп);
- построить полную систему аналитики с нуля на базе Google Data Studio;
- рост бесплатного поискового трафика.
3. Методы достижения.
Вкратце было сделано:
- проведен технический SEO-аудит. Здесь было очень много пунктов от микроразметки до решения проблем дублей, всего не описать в одной статье. Работа по реализации всех задач аудита растянулась на 1 год из-за сложности самих задач и ограниченных часов на разработку;
- особый упор в оптимизации был сделан не на каталоги по типу "книги про любовь" или "зарубежные детективы", а на карточки объектов. Мы максимально их "обогатили" дополнительной информацией, подготовили новые шаблоны мета-тегов, которые включали в себя все основные маркерные слова "читать онлайн", "скачать", "pdf" и прочее. Все эти действия привели к росту индексации сайта с 100 000 страниц до более чем 30млн в Яндекс, и с 50 000 страниц до 1.5млн страниц в Google;
- полностью сменили старый дизайн на новый, при этом ничего не потеряли в трафике;
- на протяжении 3 лет работы мы активно боролись с дублированием. Но из-за несовершенной архитектуры проекта (база данных формировалась не нами), все дубли побороть невозможно, не меняя архитектуру и принцип наполнения базы данных;
- R&D. Были проведены крупные эксперименты по открытию крупных кластеров страниц для индексации, эксперименты с внутренней перелинковкой, подготовкой специальных "хабовых" страниц для улучшения индексации карточек книг;
- комплексная аналитика. Построен отчет Google Data Studio, позволяющий следить за всеми основными показателями сайта и анализировать все основные действия юзера по разным критериям (отчет большой, 5 разных дашбордов с различными системами фильтров).
Неполный список работ, который проводился, привожу по пунктам из плана работ (тут, конечно, за 3 года работы все не влезет, я частично для понимания привел некоторые пункты). Заранее извиняюсь, т.к. названия пунктов иногда могут вводить в заблуждение, я не стал тратить на это время и корректировать названия пунктов:
- Формирование XML карт сайта (около 30млн URL)
- Файл Robots.txt
- Тег H1 и мета-теги (Title, Description, Keywords) для всех кластеров страниц
- Исправить баги просматровщика объектов (часть функционала не работает)
- Сохранить старый функционал портала на поддомене
- Параметр noindex в счетчике Я.Метрика
- Определение канонических URL
- Установка GTM для дальнейшей настройки системы аналитики
- Ограничение индексации отдельных страниц сайта поисковыми роботами (частично закрываем дубли)
- Страница 404 ошибки
- Оптимизация страниц пагинации (важно для улучшения индексации объектов)
- Реализация отзывов + рейтинга
- Массовые 301 редиректы из-за отсутствия слеша на конце URL.
- Ограничение возможности перехода на запрещенные к индексации страницы поисковыми роботами (важно, нужно макcимально экономить краулинговый бюджет на индексацию, т.к. сейчас менее 10% URL в индексе Яндекс и Google)
- Структура заголовков h1-h6 на странице
- Формирование человеко-понятных URL (ЧПУ)
- Оптимизация исходящих внешних ссылок
- Микроразметка профилей в социальных сетях
- Микроразметка логотипа компании
- Микроразметка строки поиска
- Микроразметка хлебных крошек
- Микроразметка карточки, отзывов и рейтинга
- Формирование XML карты изображений (много объектов формата "Карта" или "План" + обложки книг)
- Оптимизация кода и скорости загрузки сайта
- Формирование корректных http-заголовков
- Страница 50X ошибки
- Внедрить новый дизайн
- Тег canonical ведет на книгу, не доступную в эл.версии
- Проблемы дублей (глобальная задача с ТЗ на несколько листов, оценка разработки на более 100+ часов, реализовать не смогли)
- Удаляются карточки объектов
- Плашки для объектов, которые нельзя прочесть (многотомники и тп)
- Правила формирования URL у карточек объектов, исключим спец-символы и кириллицу
- Автоматизировать оптимизацию фильтров по автору.
- Авторизация на сайте через соц.сети + AppleID (подготовить задачу на разработку) + кнопка "Читать позже"
- Добавить звездочки в description в начало
- Микроразметка картинок книг по инструкции Яндекс
- Умная перелинковка между объектами (помогло проиндексировать старые объекты, примерно +5млн в индекс добавило спустя месяц после реализации)
- Обновление карт xml
- Добавить noindex на страницы результатов поиска
- Открыть для индексации объекты "составные" многотомников
- Кнопка "Читать позже" (аналог в "В избранное")
- Закрыть от индексации "восстановленные" объекты, которые ранее 404 отдавали. Желательно методом canonical на рабочую страницу с эл.версией.
- Доработка блока "Другие книги автора"
- 404 ошибки в кабинете ЯВМ
- Объединить блоки на карточке (слишком длинная из-за блоков "Издания", "Содержание", "Книги автора")
- Почистить профили форума
- Концепция карточки объекта
- Дизайн для новой карточки
- Функционал для новой карточки
- Реализация навигатора по авторам российской классики
- Решение проблем 404 из-за удалений объектов из смежных БД (когда меняется URL у объекта, или по каким-то еще причинам)
[!] Основные точки роста:
- оптимизированы и обогащены контентом карточки объектов (90% трафика на карточки объектов);
- борьба с дублями, в конечном счете все дубли побороть невозможно из-за архитектуры проекта;
- корректная перелинковка между объектами, что увеличило скорость и количество индексируемых объектов портала;
- построена система аналитики на основе дашбордов в Google Data Studio, которая позволила получить информацию о том, какие типы объектов читают чаще всего, какой возраст и в каких регионах пользуются популярностью те или иные авторы, издатели, какие направления более популярны у молодежи, а какие у среднего и старшего возраста и тп.;
- разработана система хабовых страниц, навигация по авторам и жанрам.
4. Результаты по трафику.
4.1. Рост органического трафика с 2019 года:
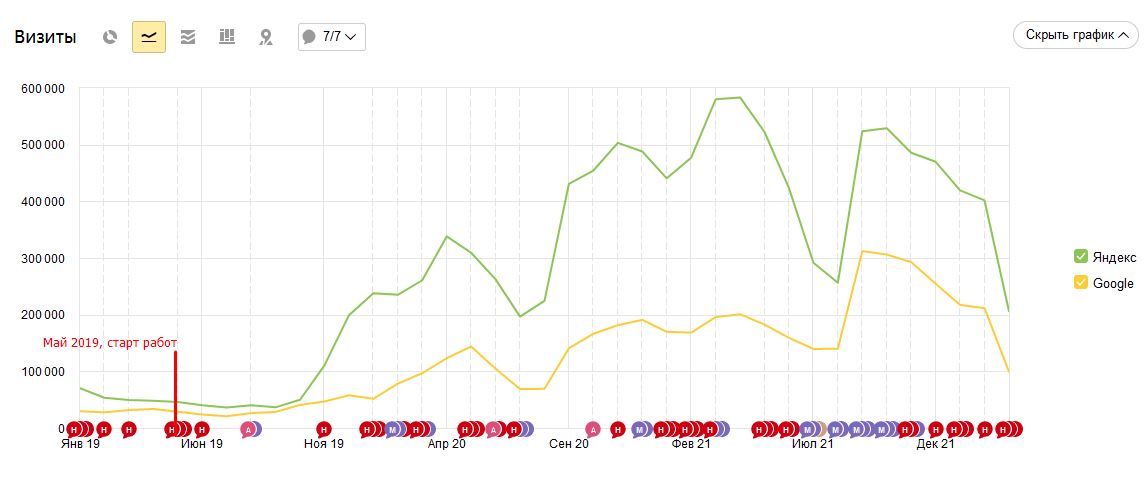
[!] Рост продолжался на всем этапе работ. По SEO реализовать успели не все в связи со сложностями и ограниченным ресурсом по разработке. Есть еще точки роста на минимум +100% прирост в органике.
5. Выводы.
На начальном плане объем трафика был до 100 000 органики в месяц (последние 5 лет этот объем особо не менялся). Когда начали работу по SEO, мы выявили колоссальный объем точек роста. Для меня это был идеальный проект, на котором можно было показывать еще больший результат от работы. В конце работы наш ежемесячный SEO трафик был на уровне 800 000 в месяц и продолжал расти.